
Unveiling the Power of Scikit-Learn: A Comprehensive Guide to Implementing it Throughout the Data Science Pipeline

In the ever-evolving landscape of data science, the ability to efficiently and effectively harness the power of machine learning algorithms is paramount. Scikit-Learn, a revered Python library, stands as a cornerstone of the data science toolkit, empowering practitioners with a comprehensive collection of powerful machine learning algorithms and utility functions.
This comprehensive article delves into the intricacies of implementing Scikit-Learn throughout each step of the data science pipeline, illuminating its capabilities and demonstrating how to harness its potential to drive data-driven decision-making.

4.3 out of 5
| Language | : | English |
| File size | : | 12316 KB |
| Text-to-Speech | : | Enabled |
| Screen Reader | : | Supported |
| Enhanced typesetting | : | Enabled |
| Print length | : | 767 pages |
Step 1: Data Preprocessing
The cornerstone of any successful data science project lies in meticulously preparing the data. Scikit-Learn offers a robust suite of tools to accomplish this crucial task, including:
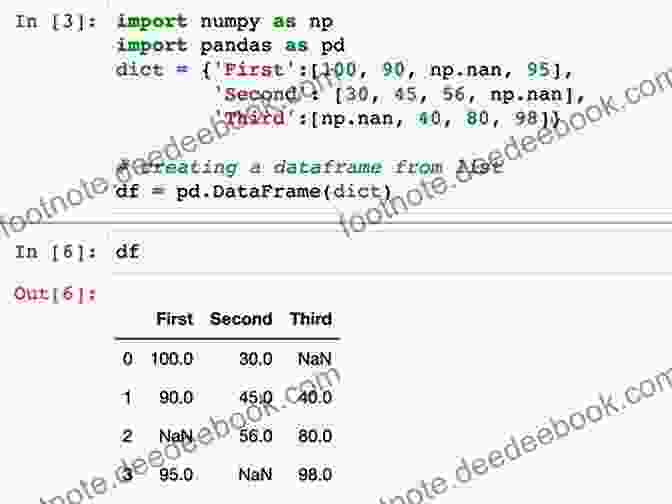
- Data Loading and Manipulation: The `pandas` library, seamlessly integrated with Scikit-Learn, facilitates data loading from diverse sources and provides an array of data manipulation capabilities.
- Missing Data Imputation: Scikit-Learn provides several imputation techniques, such as `SimpleImputer` and `KNNImputer`, to handle missing values effectively.
- Feature Scaling and Normalization: Techniques like `StandardScaler` and `MinMaxScaler` enable data standardization and normalization, ensuring comparability and enhancing model performance.
- Feature Selection: Scikit-Learn's feature selection algorithms, including `SelectKBest` and `SelectFromModel`, aid in identifying the most informative features, reducing dimensionality and improving model interpretability.
Step 2: Model Training
Scikit-Learn empowers data scientists with an extensive collection of supervised and unsupervised machine learning algorithms. Some of the most commonly employed algorithms include:
- Linear Models: Linear regression, logistic regression, and support vector machines (SVMs) are fundamental algorithms for regression and classification tasks.
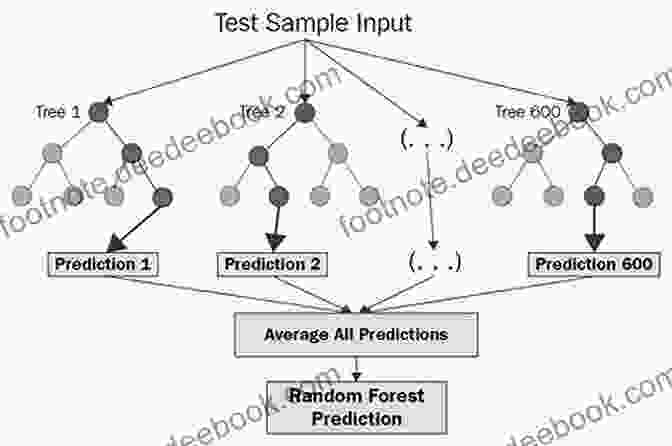
- Decision Trees: Decision tree-based algorithms, such as `DecisionTreeClassifier` and `RandomForestClassifier`, provide interpretable models for both classification and regression.
- Ensemble Methods: Scikit-Learn offers powerful ensemble methods, including `AdaBoostClassifier` and `GradientBoostingClassifier`, which combine multiple weak learners to enhance predictive performance.
- Clustering: Unsupervised learning algorithms, like `KMeans` and `DBSCAN`, enable data exploration and grouping based on inherent patterns.
- Dimensionality Reduction: Techniques such as principal component analysis (PCA) and t-distributed stochastic neighbor embedding (t-SNE) facilitate data visualization and dimensionality reduction.
Step 3: Model Evaluation
Evaluating the performance of machine learning models is crucial for assessing their efficacy and identifying areas for improvement. Scikit-Learn provides a comprehensive set of evaluation metrics and tools, including:
- Classification Metrics: Accuracy, precision, recall, F1-score, and the receiver operating characteristic (ROC) curve are commonly used for evaluating classification models.
- Regression Metrics: Mean squared error (MSE),root mean squared error (RMSE),and R-squared are key metrics for assessing regression model performance.
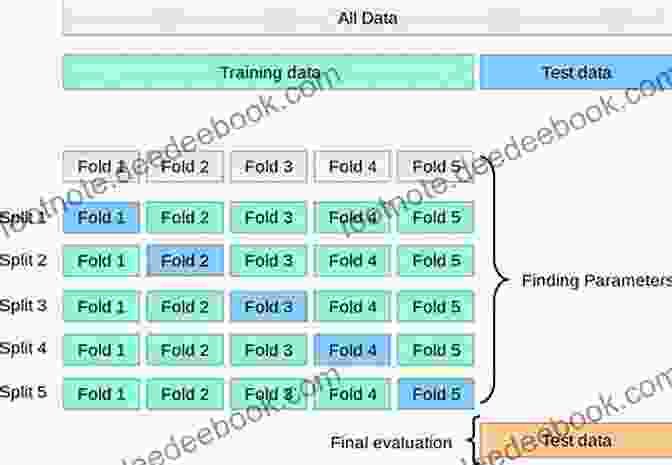
- Cross-Validation: Scikit-Learn supports various cross-validation techniques, such as k-fold cross-validation, to provide unbiased performance estimates and mitigate overfitting.
- Hyperparameter Tuning: Scikit-Learn's `GridSearchCV` and `RandomizedSearchCV` facilitate hyperparameter optimization, enhancing model performance.
Step 4: Model Deployment
Once a machine learning model is trained and evaluated, it needs to be deployed into a production environment for real-world applications. Scikit-Learn offers several options for model deployment:
- Pickle Serialization: Models can be serialized using Python's `pickle` module, allowing them to be easily saved and loaded.
- Joblib: Scikit-Learn's `joblib` module provides a robust framework for model serialization, parallel processing, and performance optimization.
- Cloud Services: Platforms like AWS SageMaker and Azure Machine Learning facilitate seamless model deployment and management in the cloud.
Scikit-Learn is an indispensable tool for data scientists, offering a comprehensive suite of machine learning algorithms and utilities that empower practitioners throughout each step of the data science pipeline. By leveraging its capabilities, data scientists can streamline data preprocessing, train robust models, evaluate their performance, and seamlessly deploy them into production environments.
Embracing Scikit-Learn's multifaceted capabilities unlocks the potential for data-driven decision-making, enabling businesses to derive actionable insights from their data and drive innovation.
Image Alt Attributes

4.3 out of 5
| Language | : | English |
| File size | : | 12316 KB |
| Text-to-Speech | : | Enabled |
| Screen Reader | : | Supported |
| Enhanced typesetting | : | Enabled |
| Print length | : | 767 pages |
Do you want to contribute by writing guest posts on this blog?
Please contact us and send us a resume of previous articles that you have written.
 Book
Book Page
Page Story
Story Genre
Genre Library
Library Paperback
Paperback Magazine
Magazine Newspaper
Newspaper Paragraph
Paragraph Sentence
Sentence Bibliography
Bibliography Foreword
Foreword Preface
Preface Synopsis
Synopsis Annotation
Annotation Manuscript
Manuscript Codex
Codex Library card
Library card Narrative
Narrative Autobiography
Autobiography Memoir
Memoir Thesaurus
Thesaurus Narrator
Narrator Character
Character Resolution
Resolution Librarian
Librarian Card Catalog
Card Catalog Archives
Archives Study
Study Scholarly
Scholarly Lending
Lending Academic
Academic Reading Room
Reading Room Interlibrary
Interlibrary Literacy
Literacy Thesis
Thesis Storytelling
Storytelling Awards
Awards Book Club
Book Club Textbooks
Textbooks Kurt Daw
Kurt Daw Peter Aleshire
Peter Aleshire Francis Voisey
Francis Voisey W H Wall
W H Wall Miles Chapin
Miles Chapin Basilio De Marco
Basilio De Marco Michael J Graetz
Michael J Graetz Mark A Zupan
Mark A Zupan Michael A Bailey
Michael A Bailey Billy Crone
Billy Crone Antony Edmonds
Antony Edmonds David Ireland
David Ireland Hans Joas
Hans Joas Jack T Rivers
Jack T Rivers Laurie Young
Laurie Young Karlene Petitt
Karlene Petitt Michail Sygar
Michail Sygar Tierney James
Tierney James William Saroyan
William Saroyan Elizabeth Partridge
Elizabeth Partridge
Light bulbAdvertise smarter! Our strategic ad space ensures maximum exposure. Reserve your spot today!



 Howard PowellMusic By Max Steiner: The Epic Life Of Hollywood S Most Influential Composer...
Howard PowellMusic By Max Steiner: The Epic Life Of Hollywood S Most Influential Composer...





 Joe SimmonsFollow ·10.6k
Joe SimmonsFollow ·10.6k Xavier BellFollow ·15.7k
Xavier BellFollow ·15.7k Tom HayesFollow ·9.7k
Tom HayesFollow ·9.7k Edwin BlairFollow ·10.1k
Edwin BlairFollow ·10.1k Ernest PowellFollow ·14.9k
Ernest PowellFollow ·14.9k Gabriel MistralFollow ·12.3k
Gabriel MistralFollow ·12.3k Connor MitchellFollow ·9.8k
Connor MitchellFollow ·9.8k Jeremy MitchellFollow ·14.7k
Jeremy MitchellFollow ·14.7k

 Allen Ginsberg
Allen GinsbergUnveiling the True Meaning of Enough: A Comprehensive...
: In the relentless pursuit of progress and...

 Forrest Blair
Forrest Blair
 Clay Powell
Clay PowellHawker Hunter: The Jet Fighter that Shaped British...
Nestled in the halls of aviation...

 Alec Hayes
Alec HayesWhen and How to Use Lean Tools and Climb the Four Steps...
Lean is a management...

 Trevor Bell
Trevor BellVolume of Charlotte Mason Original Homeschooling: A...
Charlotte Mason's original...

 John Parker
John ParkerAscending Tristan da Cunha: A Comprehensive Guide to...
Prepare yourself for an extraordinary journey...
4.3 out of 5
| Language | : | English |
| File size | : | 12316 KB |
| Text-to-Speech | : | Enabled |
| Screen Reader | : | Supported |
| Enhanced typesetting | : | Enabled |
| Print length | : | 767 pages |
